
近代人工智能發展自從 1950 年代電腦出現以後,科學家就不斷思考,如何使電腦更像人類,例如能夠自行思考、判斷對錯、以致能夠幫助人類處理所有工作,然而發展過程並不順利,中間歷經幾次失敗。若以技術發展為分界,可以大致分為三個階段: 第一階段:符號邏輯(1950到1960年)1950 年代,電腦剛問世,科學家們試圖想把人類的知識及思考模式放入電腦,但最終因人類都沒辦法完全了解自己的思考過程,根本無法將人類的思考脈絡、語言結構、決策能力具體的寫成電腦方程式,最後以失敗告終。 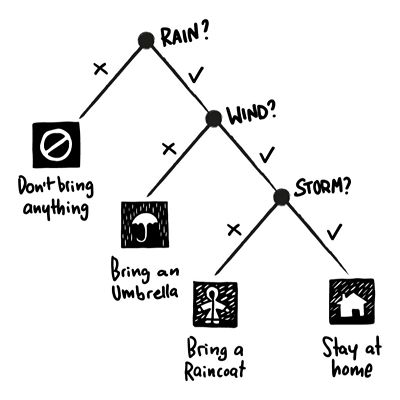
第二階段:專家系統(1980到1990年)1980 年代,人類退而求其次,不再將思考模式寫入電腦,而是試圖將人類定義好的規則寫入電腦中,但最後還是失敗了,原因是規則永遠不會停止改變,比如說天氣狀況的走向、地震預測、火災警報,永遠都充滿變數,就算將所有狀況寫成方程式,也難保不會有未曾見過的情況,治標不治本,這是人類在人工智慧發展上遇到的第二次失敗。 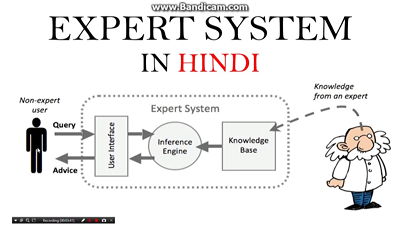
第三階段:機器學習(2010年至今)第三階段的發展約始於 2010 年,科學家們認為,既然無法將思考模式寫入程式,也無法將所有狀況告訴電腦,那不如將「學習」的能力交給電腦,真正實現智慧的展現。於是科學家僅教會電腦「識字」,再將大量的狀況丟給電腦,讓機器自行判斷,於是神奇的事情發生了,電腦找到了學習的邏輯,能夠自行進行優化更正,使人工智慧的發展有了極大的進展,且還在不斷的進步。 
機器學習依照問題界定的方式,可以分為四種類型:
深度學習 - 更加複雜的機器學習深度學習是更進階的機器學習分支,同樣都是為了建立迴歸/分類模型,唯一的差異在於深度學習使用人工類神經網路,而非其他統計模型。因此,您也可以將 深度學習視為 機器學習的次領域。但為什麼它現在變得那麼熱門? 顧名思義,人工類神經網路是人工神經元構成的網路;而人工神經元則是一個數學單元,可在對輸入值進行簡單計算後,提供一些輸出值。它跟實際的神經細胞非常相似,因為後者的作用基本上大同小異:接收電子訊號並產生輸出。而人工類神經網路也在做相同的事:它接收資料值,讓網路中的所有神經元處理資料值,再輸出一些終值。由於這類網路需要很多層神經元(而且層層堆疊)才能運作,因此學者加了「深度」二字,強調其結構之複雜性。 
有人可能會想,為什麼這麼簡單的神經元,在大量平行和成串組合在一起後,居然能集體造就出 AI 產業中最出色的應用。這其實不難想像,只要將它與「實際的」生物演化過程比較就行了。單細胞生物本身的機能相當有限,不過,隨著大自然將更多細胞組合在一起,構成多細胞生物,更加複雜的生命形態也隨之誕生。然後,無脊椎動物演化成脊椎動物,魚類演化成靈長類,穴居人演化成智人(亦即我們),不只建造金字塔,還能發射火箭上太空。如果您可以體認到一大群細胞的力量,大概就能瞭解為什麼深度學習如此強大。 當然,有好必定有壞。使用深度學習,必須提供大量資料,才足以訓練出能用的統計模型(這也是為什麼「大數據」一詞會隨著深度學習的興起而出現)。再來,若要處理所有資料,必須具有強大的硬體,方可進行數以萬計的運算迭代。即使如此,深度學習已經向我們展示它無與倫比的可能性。以 Facebook 和 Pinterest 為例,Pinterest 利用深度學習進行更好的影像分類,而 Facebook 則運用類似技術,在使用者上傳相片時進行臉部辨識。(好比上傳照片時,Facebook常在您還沒tag好友之前就能自動顯示小方塊指出您的好友。) 除了社群媒體外,深度學習也同時支援我們日常生活中使用的工具,例如 Siri、Gmail(垃圾郵件偵測)、自動駕駛車等。工程師將深度學習視為 AI 的未來,因為它為 ML 的實際應用帶來接近無限的可能性。 |